How does it work?
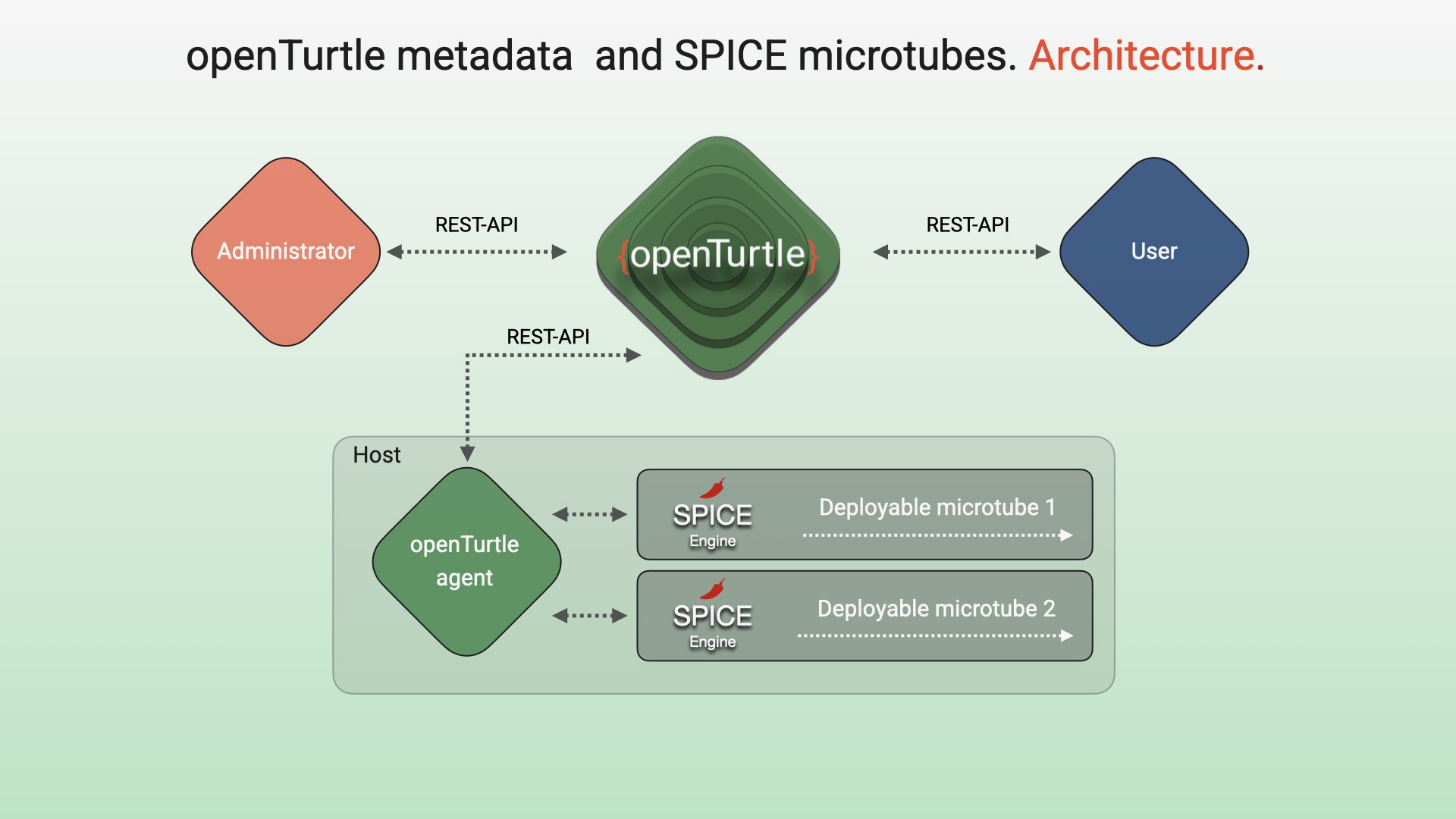
openTurtle metadata focuses on the "know your data" principle and provides a "single point of truth" for the structure of a company's data.
An administrator pre-configures algorithms, defines and authorizes microtubes. The details are stored in openTurtle metadata repositories.
As soon as an authorized user requests data, the openTurtle agent activates SPICE microtubes: they process the data based on the defined requirements and the configured algorithms.
The SPICE framework uses DataFlowSQL, our proprietary SQL slang, to address and process data elements in a data flow.